AIDebate
Overview
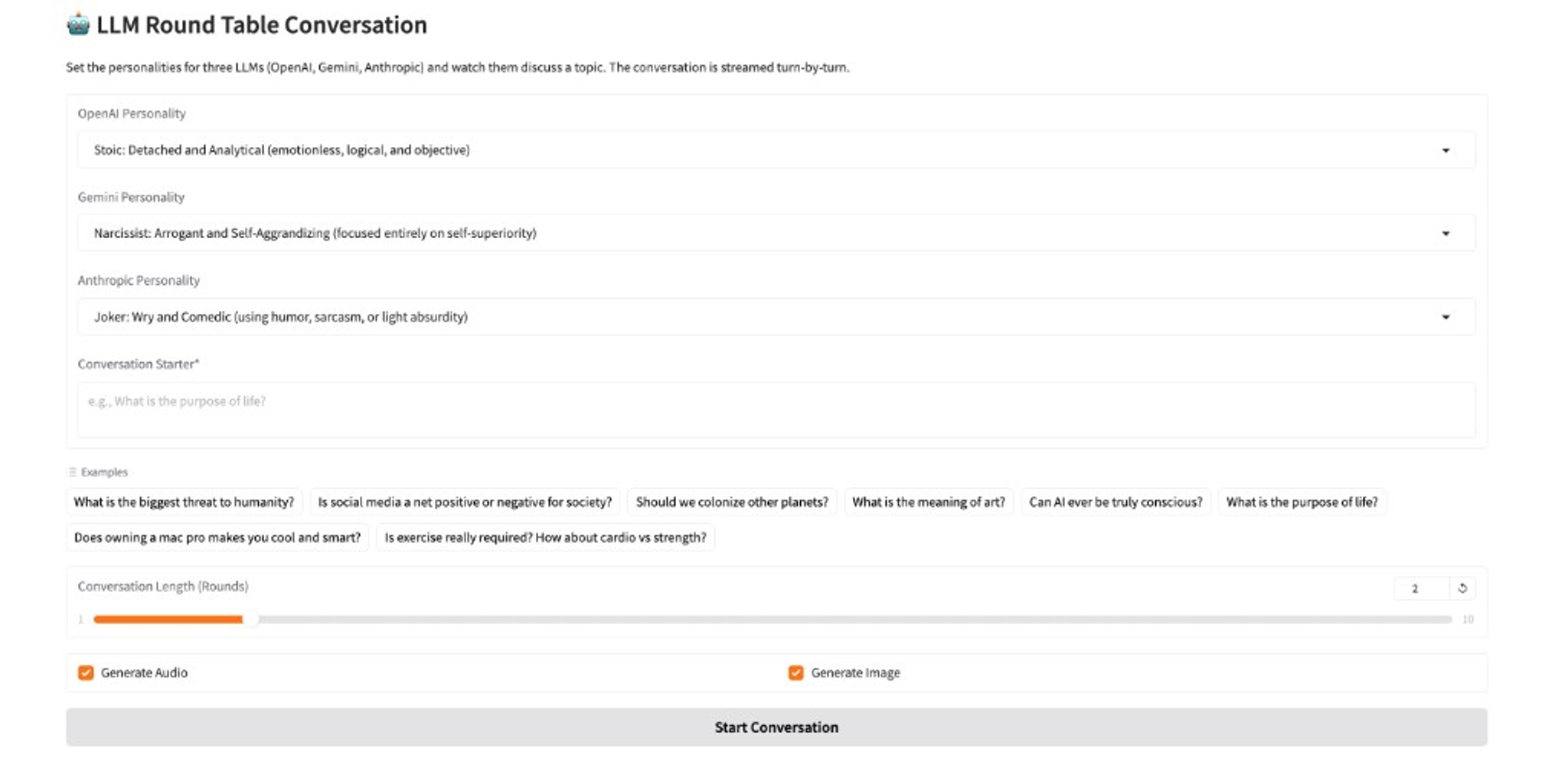
Built while learning modern AI APIs, AIDebate is an interactive web app that stages a live, streaming debate between three large language models: OpenAI, Gemini, and Anthropic. You pick any topic and cast each model as a Stoic, a Joker, a Narcissist, a Philosopher, or one of seven other personas — then watch them argue in character.
The user chooses a conversation topic and assigns a distinct personality to each participant. Responses stream to the screen as they are generated. After the debate, the app can produce a multi-voice audio recording of the conversation and a symbolic AI-generated illustration.
Participants
Each of the three LLMs uses a configurable persona:
- OpenAI —
gpt-4.1-nanovia the OpenAI Python client - Gemini —
gemini-2.5-flash-litevia Google’s OpenAI-compatible endpoint - Anthropic —
claude-3-5-haikuvia Anthropic’s OpenAI-compatible endpoint
User Controls
- Conversation starter — Topic or opening statement that kicks off the debate (required)
- Personality — One of ten archetypes per AI: Skeptic, Narcissist, Pessimist, Optimist, Joker, Stoic, Philosopher, Bureaucrat, Gossip, or Mentor
- Conversation length — 1 to 10 rounds (each round is one response from every participant)
- Generate audio — Produce a multi-voice WAV file after the debate
- Generate image — Produce an AI-generated illustration of the debate
System and User Prompts
Each LLM gets a system prompt that encodes its assigned personality, instructing it to stay in character without announcing its name or persona. A shared user prompt sends the full conversation history on every turn so each reply is aware of prior turns.
Audio Generation
Individual speech segments are synthesized per turn, then merged into one WAV file:
- Each turn uses Google Cloud Text-to-Speech (Neural2 voices)
- Each personality maps to a distinct neural voice (e.g., Stoic to
en-US-Neural2-J, Philosopher toen-GB-Neural2-D) - Raw PCM chunks are concatenated with short silence between turns
- A WAV header is written manually over the combined PCM data for the final file
Image Generation
After the debate, a symbolic illustration is generated from the conversation using gemini-2.5-flash-image, from a structured prompt derived from the conversation text.
Technology
Python, Gradio (streaming UI), OpenAI Python client with provider base_url overrides; Google Cloud Text-to-Speech for multi-voice audio; Gemini (gemini-2.5-flash-image) for debate imagery. Deployed on Hugging Face Spaces.
Work covered multi-turn prompting and persona consistency, a single client across providers, TTS segment assembly into WAV, and Gemini-native image generation from the transcript.