AI Chatbot
Overview
The AI Chatbot is a public-facing, highly secure assistant embedded directly on the homepage of this website. It acts as an interactive guide, answering user questions about the author’s background, work experience, projects, and articles using a strictly bounded, self-evaluating agentic pipeline.
Architecturally, the project is designed around an API-first, decoupled layout:
- The Frontend / UI is a custom client-side React component integrated into this personal website, managing Server-Sent Events (SSE) and rendering live execution stages.
- The Core AI & Processing APIs are served by a dedicated server
ai.asifrajwani.com. This separation allows the serverside stack to act as a general platform that can scale to support other future lightweight AI utilities (like summarizers or semantic search tools) without polluting the presentation codebase.
Architecture: Decoupled UI & Compute
By splitting the chatbot across two distinct repositories, the application remains lightweight, modular, and easy to maintain:
- Frontend: Handles presentation, custom micro-interactions, theme integration, and streams stages dynamically from the SSE protocol.
- Backend (ai.asifrajwani.com): A dedicated Next.js API-first application that handles incoming payloads, executes Zod validation, verifies bot challenge tokens, tracks per-IP rate limit caps, and orchestrates model invocations.
This structure allows the compute-heavy AI operations to scale independently on the server side while keeping the user-facing website highly responsive.
The Bounded Agentic Pipeline
Because the chatbot is open to the public, the backend enforces a robust, multi-layered defensive workflow to ensure safety, factual accuracy, and cost-efficiency:
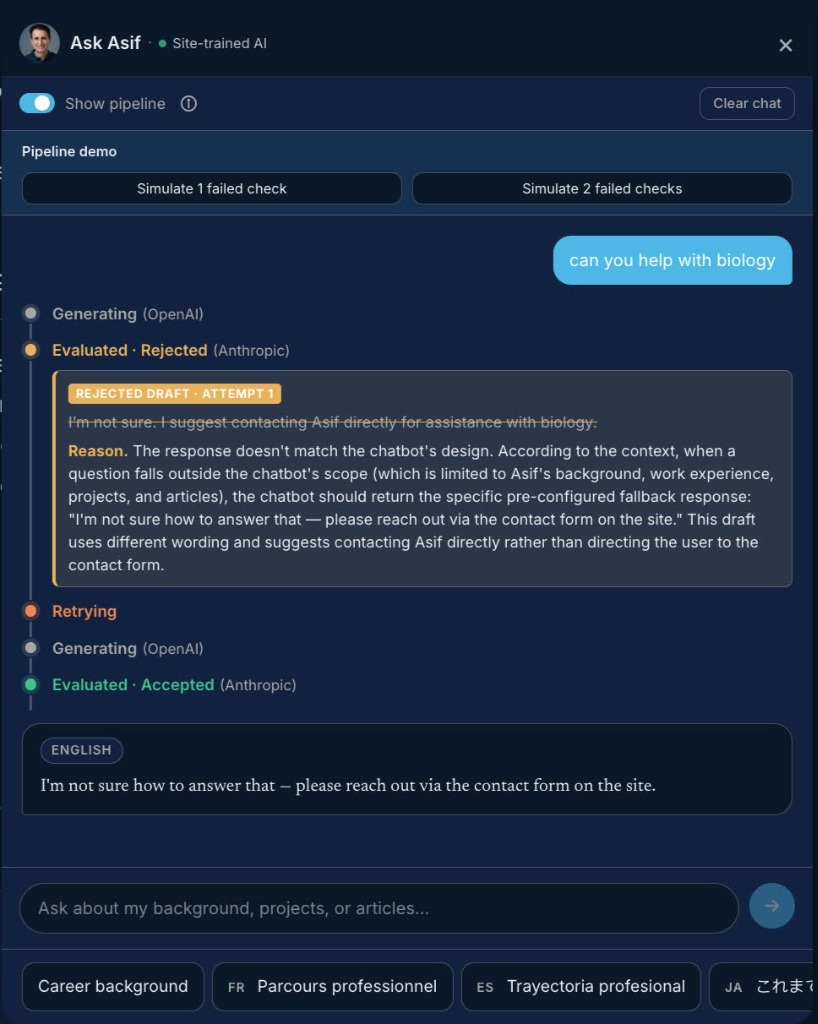
- Dual-Model Generator-Evaluator Loop — To prevent “model blindness,” the application separates generation and validation. It uses OpenAI (
gpt-4o-mini) to generate draft responses and Anthropic (claude-3-5-haiku) to evaluate them. - Guaranteed Schema Conformance — The Anthropic evaluator uses native structured tool calling and a Zod-validated schema to return a precise JSON verdict:
{ is_acceptable, reason, detected_language }. It checks whether the draft is strictly grounded in the site context, directly answers the prompt, and maintains the proper tone. - Single Retry with Rejection Feedback — If the evaluator rejects a draft, the pipeline automatically feeds the evaluator’s specific rejection reason back into the generator for a second draft attempt.
- Deterministic Safe Fallback — If the second draft is also rejected, the pipeline halts to contain costs and immediately streams a safe, pre-configured fallback response (“I’m not sure how to answer that — please reach out via the contact form on the site.”).
- Context Isolation — The chatbot’s knowledge base is statically compiled into a single text file (
me-context.txt) generated from public Markdown pages. The generator is strictly instructed to only answer using this context. Because the corpus is small, it fits entirely within the prompt window, eliminating the latency and complexity of RAG or a vector database. - Network & Bot Protection — To prevent automated abuse of the model endpoints, every incoming API request is verified server-side with Cloudflare Turnstile challenges and protected by an in-memory token bucket rate limiter (default 20 requests per hour per IP).
- Declarative Configuration — Key parameters—including rate limits (token bucket capacity and fill rate), AI model selections for both generation and evaluation, and the exact fallback response text—are completely decoupled from code. They are managed via central configuration/environment variables, allowing quick operational adjustments without redeploying code.
Capabilities & Modes
- Dual-Mode SSE Streaming — The chatbot API serves responses via Server-Sent Events (SSE). The user interface supports two viewing experiences:
- Simple Mode (Default): The client streams only the final, approved response for a seamless user experience.
- Technical Mode: The UI streams every backend execution stage (
generating,evaluating,retrying,final, orfallback) in real time, exposing the evaluator’s raw reasoning and intermediate draft attempts.
- Emergent Multilingual Support — While the underlying context is entirely in English, the pipeline dynamically detects the user’s input language and drafts, evaluates, and responds in that language automatically.
- Traceability — Every pipeline run generates a unique
traceIdwhich is returned in the initial SSE event, allowing client interactions to be correlated with structured server logs.
Technology Stack
- Frontend & UI: Astro 5, Tailwind CSS 4, React 19, and shadcn/ui.
- APIs & Backend: Next.js 15 (App Router, running on AWS Lambda Function URLs with response streaming to support Server-Sent Events).
- AI SDKs: Native
openaiSDK and@anthropic-ai/sdkfor native, structured tool calling and schema validation. - Validation: Zod schemas for incoming payloads and structured evaluator responses.
- Observability: Structured JSON logging in AWS CloudWatch with Embedded Metric Format (EMF) to measure stage latencies, paired with CloudWatch RUM for client performance tracking.
- Hosting: AWS Amplify with secure environment variables configured natively through the Amplify Console.