The AI-Native SDLC: From Manual Coder to Strategic Curator
A playbook for developers, business analysts, architects, and CI/CD — the AI-native organization.
Overview
We are at a genuine inflection point in software engineering. Not the kind declared every few years with a new framework or cloud paradigm — a structural one. The way software gets built is undergoing the same kind of abstraction shift that moved us from writing assembly instructions to writing SQL queries.
This article covers a playbook for the AI-Native SDLC: the full lifecycle from intent to deployment, the security guardrails that make it safe to execute at speed, and the human accountability model that keeps engineers — not AI — responsible for the outcomes.
The 5G Abstraction Ladder
Here, 5G means the fifth generation of programming abstraction in software engineering — not the cellular network standard.
To understand why this moment is different, it helps to trace the abstraction path of software engineering:
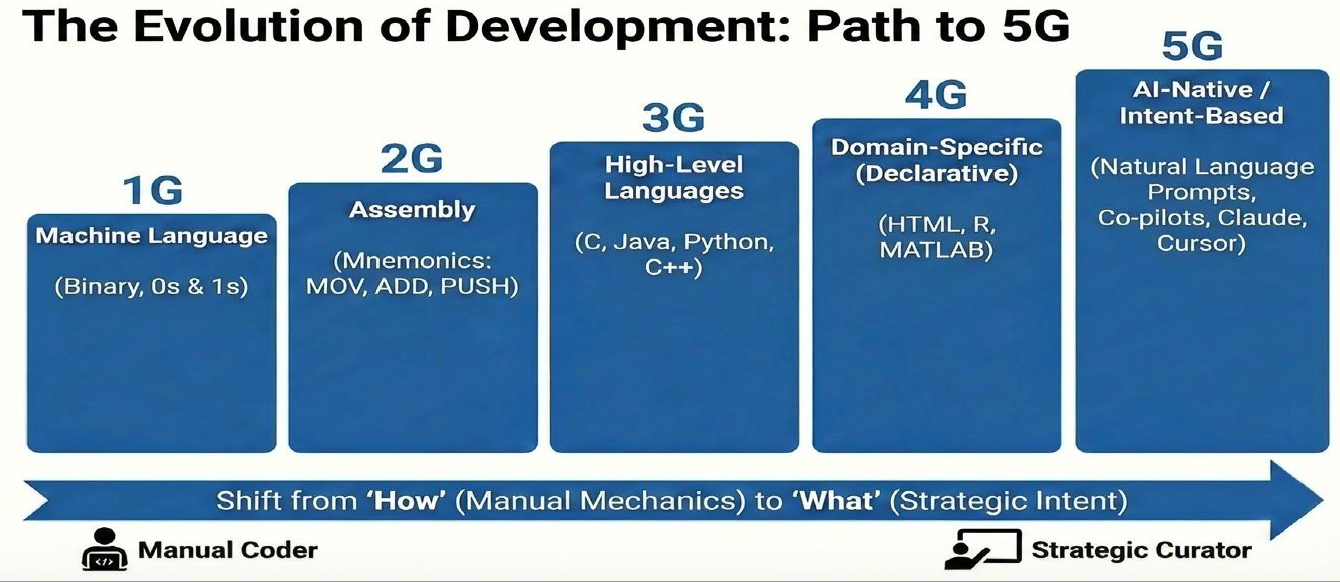
Figure: Each generation moves the interface further from hardware and closer to human intent — culminating in natural language and constraints as the primary way to direct construction.
| Generation | Interface | Representative Tools |
|---|---|---|
| 1G | Machine Language | Binary, 0s and 1s |
| 2G | Assembly | MOV, ADD, PUSH |
| 3G | High-Level Languages | C, Java, Python |
| 4G | Domain-Specific / Declarative | HTML, SQL, MATLAB |
| 5G | AI-Native / Intent-Based | Natural language prompts, Claude Code, Cursor |
The 5G shift is not about AI writing code for you. It is about natural language and high-level constraints becoming the primary interface for directing software construction. The developer’s job moves from implementing details to specifying intent, validating correctness, and owning the outcome.
The New Role: Strategic Curator
The most important reframe in the AI-Native model is what the human role actually becomes.
Traditional development is high-volume manual labor — translating requirements into syntax, writing boilerplate, debugging framework configurations. The AI-Native approach replaces the low-value labor with orchestration and reserves human judgment for what it does best: reasoning about correctness, security, and business logic.
Delivery style matters as much as tooling. The playbook moves teams away from the monolithic pull request — large, slow reviews with concentrated risk — toward thin-slice delivery: small, verified functional modules that can be tested and integrated with minimal friction. The curator orchestrates those slices; the AI handles volume inside each boundary.
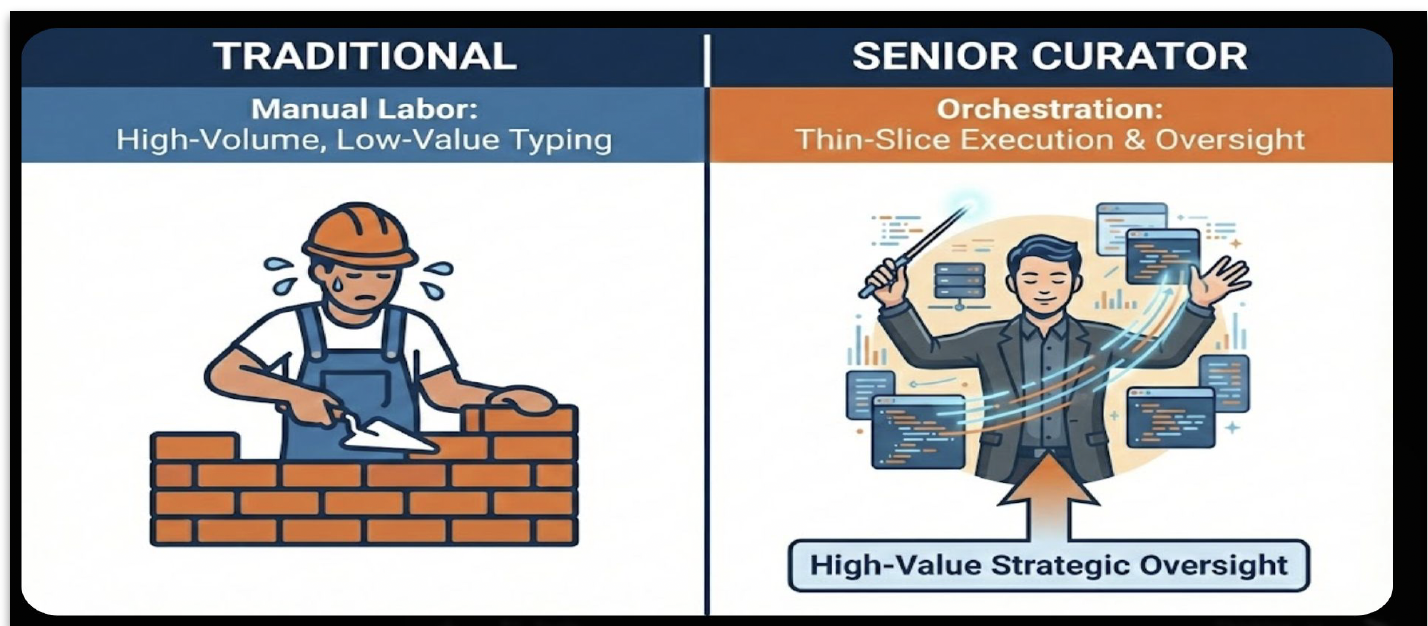
Figure: Manual typing labor versus orchestration — thin slices with strategic oversight.
What the curator does:
- Defines intent precisely enough that the AI can execute it correctly
- Sets security boundaries and architectural constraints before generation starts
- Validates that generated artifacts match the actual business logic — not just that they compile and pass tests
- Owns production health; that accountability is non-transferable
The key insight: AI generates the artifacts. Humans own the results. This is not a philosophical position — it is an operational one. The human team remains the sole authority for Logic, Security, and Production Health.
The Context Package: Your Security Guardrails
The single most important mechanism for safe AI-Native development is the Context Package — a set of structured Markdown documents that define the rules of the road before any code is generated.
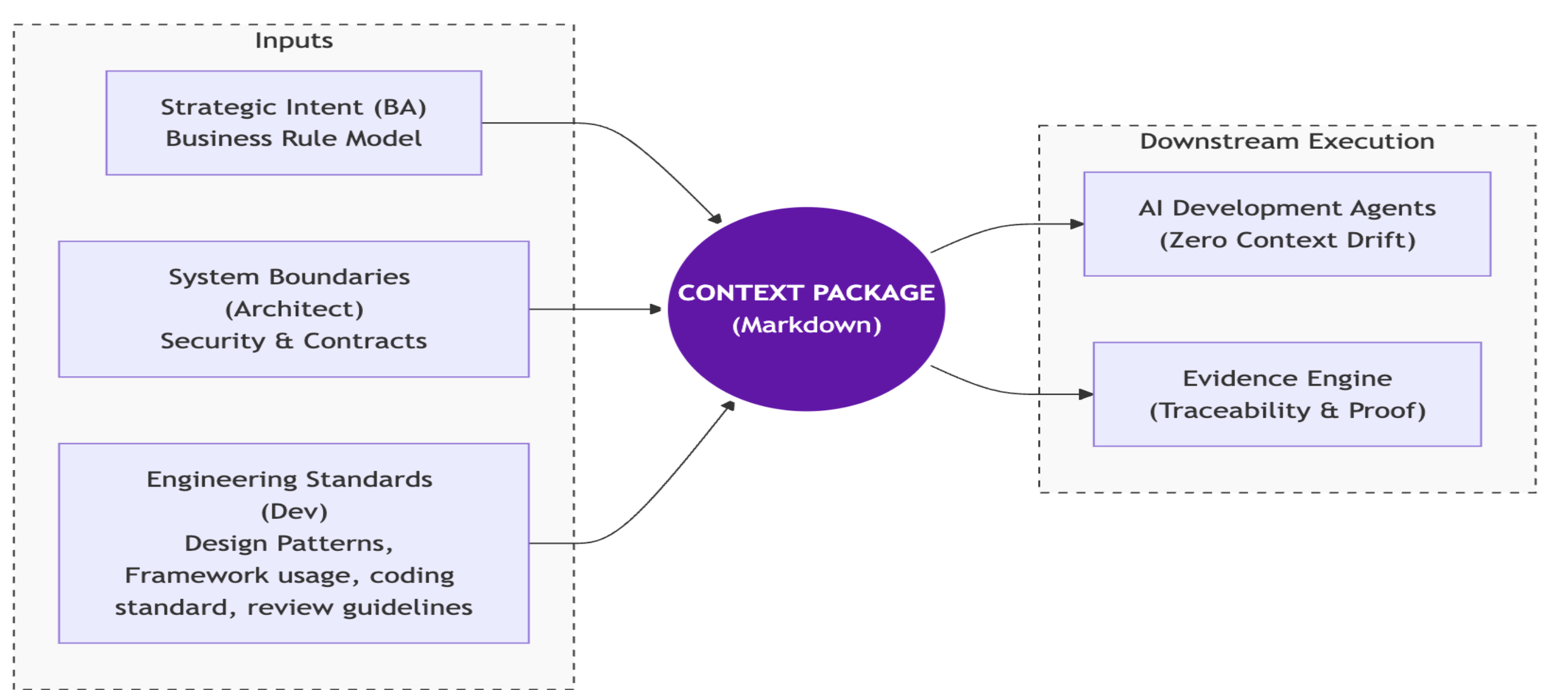
Figure: BA intent, architect boundaries, and dev standards converge into Markdown that feeds agents and the evidence engine.
🧭 We aren’t creating more “paperwork.” We are setting a Baseline GPS for the AI. Just as you don’t map every inch of the road before a trip, we set the “Rules of the Road” (our tech stack and core logic) once. The AI then handles the driving — generating the detailed documentation and code as we go.
The Context Package has three inputs:
1. Strategic Intent (Business Analyst) Not a 50-page requirements document. A formal, machine-readable map of domain rules — the FX settlement windows, compliance limits, authorization rules. This is what allows the AI to reason correctly about your business, not generic internet patterns.
2. System Boundaries (Architect) The architectural guardrails: security perimeters, API contracts, data classification rules, and the technical baseline. Everything the AI generates must fit within these defined boundaries. This is where security is enforced before generation, not discovered in code review after.
3. Engineering Standards (Developer) Coding standards, framework usage patterns, design patterns, testing conventions. Defined once in Markdown; enforced programmatically during generation and used as the benchmark during Pull Request reviews.
Following that same idea: think baseline GPS, not a street-by-street atlas — the Context Package anchors direction while specifics evolve, so you can start from a thin baseline without finalizing every detail before the first slice ships.
What this prevents is Context Drift — the tendency for AI-generated code to drift away from your specific security, architecture, and business requirements and toward generic internet patterns. The Context Package is the mechanism that keeps every generated module anchored to your reality.
That structured, machine-readable foundation is what the Testing Fortress builds on: traceability from user stories to tests, and compliance evidence that stays tied to the same source of truth instead of a parallel paperwork trail.
Strategic Intent: The Logical Baseline
The Business Analyst’s role in an AI-Native team is fundamentally different from the traditional requirements-to-document model. The goal is Business Rule Modeling — creating a formal, machine-readable specification of the domain logic.
For a financial services application, this means encoding the actual rules: settlement windows, compliance thresholds, authorization matrices, calculation formulas. These are not described in prose — they are structured in a way the AI can reason over.
Why this matters for security: we don’t ask the AI to guess our business rules. Guessing produces code that looks correct and passes tests but violates a compliance constraint buried in a 200-page regulatory document. The Logical Baseline provides the AI with a source of truth. The generated code is correct by design, not just syntactically valid.
The Architect’s complementary contribution is the System Boundary definition: where data lives, how it flows, what can be exposed via which interfaces, and where authentication and authorization are enforced. These guardrails ensure every AI-generated module integrates cleanly into the enterprise ecosystem without manual re-work or post-hoc security patching.
The Testing Fortress: Verification as an Evidence Engine
Building on the Context Package above, verification assumes intent and standards are stable enough to map work to proof: stories to tests, runs to reports, and risk to named owners.
The AI-Native testing model flips the traditional relationship between development and verification. Testing is no longer a phase that happens after development — it is an Evidence Engine that runs continuously alongside code generation.
Automated Test Generation
Unit and integration tests are generated alongside the functional code. AI agents simulate user journeys across the full integration surface, ensuring new code doesn’t just work in isolation but integrates correctly with adjacent systems.
The Compliance Automation Layer
For regulated environments, this is where the model becomes genuinely valuable:
Traceability Matrix — The AI automatically maps every User Story to the Test Cases that validate it, yielding end-to-end visibility from requirements to tests without the manual overhead of maintaining a separate traceability spreadsheet.
Test Exit Reports — AI auto-summarizes results, coverage gaps, and risk exposure. The human team reviews and approves rather than drafting from scratch. What previously took days of analyst time is produced in minutes, with humans providing the final sign-off judgment.
Agentic Regression
Static regression test suites decay rapidly as code changes. The agentic approach is different: agents analyze code changes, identify which legacy modules are at risk given those changes, and generate targeted regression tests for those specific boundaries — automatically, as part of the pipeline.
This is security-critical. The modules most likely to be broken by a change are exactly the modules most likely to introduce subtle vulnerabilities when broken. Agentic regression provides systematic protection for those boundaries.
CI/CD: The Zero-Intervention Pipeline
The deployment pipeline in an AI-Native organization is engineered around a clear goal: from code check-in to test-ready state with zero manual intervention.
What “Zero-Intervention” Actually Means
The pipeline is triggered by verified intent — confirmed Stories attached to a validated Context Package. It automates build and test cycles without requiring a human to configure environments, set up test data, or monitor for flaky tests.
The “No-Human” Security Gate
High-confidence automated gates handle:
- Functional correctness checks
- Security scanning (dependency vulnerabilities, static analysis, credential leakage)
- Performance regression checks against established baselines
Manual QA is reserved exclusively for high-risk UX or visual changes that automated checks cannot fully evaluate. Security checks are never delegated to manual review — they are enforced in the gate.
Self-Healing Pipelines
AI-driven monitoring analyzes build failures and environment degradation to suggest or apply immediate fixes to CI/CD configurations. Rather than a human diagnosing why a test environment stopped working at 2am, the pipeline identifies the root cause and either resolves it or escalates with a precise diagnosis.
Audit-Ready Logging
Every step of the automated process is logged in machine-readable format. For regulated firms, this satisfies audit requirements without a manual evidence collection exercise before each release. The evidence is produced by the process, not assembled after the fact.
Tooling: The Agentic Stack
Moving from chatbot-assisted development to a fully agentic workflow requires standardizing on a specific stack. Without standardization, teams accumulate tool overlap and “Context Drift” as each developer works with different AI configurations.
The Orchestration Layer
Cursor serves as the primary IDE for thin-slice development — real-time context during active coding. Claude Code operates at the CLI level for agentic tasks: bulk refactoring across large codebases, environment troubleshooting, and automated evidence generation.
Model Context Protocol (MCP)
MCP is the mechanism that connects AI agents to your specific data sources without “Tool Pollution” — giving agents precisely the context they need and nothing they don’t.
A concrete example: connecting a Figma MCP Server gives the AI real-time access to live design specifications and CSS variables. The generated frontend code stays aligned with the latest design system without the AI searching through irrelevant files or producing pixel-imperfect output.
Applied to security: an MCP server connecting to your firm’s internal compliance rules and security policies gives every AI agent precise, current regulatory context. The AI doesn’t guess your compliance requirements — it reads them directly, in real time.
AI as a Virtual Stakeholder
The AI is not just a code generator in this model. It participates in technical dialogue as an active “Devil’s Advocate” — challenging architectural decisions, identifying edge cases in business rules, and flagging potential security gaps in proposed designs. Engineering teams that treat AI as a passive tool miss the highest-value interaction pattern.
Measuring What Matters: New Metrics
AI-Native development requires retiring legacy vanity metrics (Story Points, PR Counts) in favor of indicators that reflect release readiness and AI-assisted quality.
| Metric | Definition | Target |
|---|---|---|
| Intent-to-Ready Velocity | Lead time from BA requirement / Architect HLD to a verified release-ready unit | Minimize |
| Deployment Readiness (Modules) | Frequency of verified, high-quality code increments staged for release | High frequency |
| Doc Automation Ratio | % of compliance evidence generated without manual editing | >80% |
| Automation-to-Risk Ratio | % of high-risk logic covered by 100% automated, agent-verified testing | 90% critical coverage |
The Automation-to-Risk Ratio deserves particular attention for security-conscious teams. It directly measures the coverage of your highest-risk logic by automated verification — not overall test coverage, but coverage of the code paths where failures create the most exposure. Treat 90% critical coverage as the bar for high-risk logic, not a vague “more tests” goal.
The Unified Responsibility Matrix
The clearest articulation of the AI-Native model is a responsibility matrix across the full lifecycle:
| Phase | Owner | AI Method | Output | Human Value-Add |
|---|---|---|---|---|
| Strategic Intent | BA | Business Rule Modeling | Business Rule Baseline | Strategic problem-solving, logic validation |
| System Boundary | Architect | Standards Mimicry | High-Level Design | Security guardrails, system contracts |
| Logic & Structure | Dev Team | Agentic Orchestration | Tuned Technical Guardrails | Senior curation: owning logic, security, code health |
| Tech Debt | Dev Team | AI-Led Rewriting | Modernized Modules | Critical “Rebuild vs. Refactor” decisions |
| Verification | Testing | Test Generation | Unit & Integration Suites | Behavioral oversight, complex edge-case discovery |
| Compliance Proof | Testing | Evidence Engine | Traceability & Exit Reports | Final audit sign-off, risk assessment |
| Delivery Gate | CI/CD | Self-Healing Pipeline | Release-Ready Module | Infrastructure governance, pipeline health |
The pattern across every row is the same: AI handles the execution mechanics; humans own the judgment calls. Architects don’t write every HLD line — they define the security boundaries that every HLD must respect. Developers don’t write every test — they identify the edge cases that automated generation misses and own the code health of the result.
Key Takeaways
The AI-Native SDLC is not a productivity optimization of the existing model. It is a structural redesign of how software gets built, where:
-
Intent replaces syntax as the primary engineering artifact. The quality of your Context Package determines the quality of everything generated downstream. Architects and BAs become as critical to output quality as developers.
-
Security is embedded in the process, not added at the end. System Boundaries, security gates in CI/CD, and Agentic Regression testing ensure security is enforced at every layer — not discovered in a pentest after the fact.
-
The Evidence Engine solves the compliance burden. Traceability matrices and exit reports generated automatically from the pipeline replace the manual evidence collection that consumes disproportionate time in regulated environments.
-
Human accountability is non-transferable. AI generates artifacts. Engineers own the results — for Logic, Security, and Production Health. This accountability cannot be delegated to the model, and teams that understand this ship safer software than teams that don’t.
The organizations that operationalize this model — that build the Context Packages, enforce the security gates, and retrain their teams to curate rather than type — will have a structural execution advantage. Those who treat AI as a faster typist will not.
Terms
Short definitions for language used throughout this playbook:
- LLM (large language model) — A model trained on broad data to generate text or code; it acts as the reasoning core for agentic workflows.
- Inference — Running that model to produce an output in real time (for example, an API call that returns a suggested patch).
- RAG (retrieval-augmented generation) — Combining the LLM with retrieval over your own documents so answers are grounded in current sources. Your Context Package is a natural retrieval target so generated modules match your rules, not generic training data.
- Agent — A system that plans, uses tools, and pursues multi-step goals rather than answering a single prompt.
- Coding agent — An agent focused on engineering tasks: navigating the repo, editing code, and running tests until defined criteria are met.
- MCP server — A standardized bridge (Model Context Protocol) from agents to files, APIs, design tools, or internal policy corpora.
- Business Rule Modeling — Expressing domain logic in a structured, machine-readable form so the AI does not have to infer critical rules from prose.
Perspectives
“The unit of work in software engineering is shifting from a line of code to a high-level intent.” — Aditya Agarwal, Former CTO of Dropbox and early Facebook engineer
“The bottleneck of software development is no longer writing the code; it is verifying that the code does what we intended.” — Andrej Karpathy, Founding Member of OpenAI and former Director of AI at Tesla
“The future of software is more about orchestration than typing. We are moving from being ‘writers’ of code to being ‘editors’ of systems.” — Amjad Masad, Founder of Replit
“AI doesn’t replace the developer; it makes the developer the architect of their own intent.” — Nat Friedman, Former CEO of GitHub
“Code is a means to an end. The real value is in the mental model of the solution.” — François Chollet, Creator of Keras and AI Researcher at Google
“AI will not replace humans, but humans with AI will replace humans without AI.” — Karim Lakhani, Harvard Business School professor and AI researcher