Guardrails Without a Gatekeeper: Six Rules for Autonomous LLM Applications
When input goes straight to an AI and the answer goes straight back, the application is the reviewer.
Most LLM demos have a human nearby. Production does not. A visitor asks a question, the model answers, and the response renders immediately.
I recently shipped a public chatbot on this site. Here are the six layered guardrails that keep the serverside pipeline useful, fast, and cheap.
1. Evaluate What You Generate
Do not ask a model to grade its own homework. The serverside separates concerns: it uses gpt-4o-mini (OpenAI) to generate drafts and claude-3-5-haiku (Anthropic) to evaluate them. The evaluator checks whether the draft is grounded in site context, directly answers the prompt, and maintains the proper tone. Using different providers minimizes shared cognitive blind spots.

If the evaluator rejects a draft, its feedback is fed back into the generator for a second attempt. After two consecutive failures, the pipeline halts and serves a predefined, safe fallback response.
2. Constrain the Model with a System Prompt
The generator is strictly instructed to answer only from static context bundled directly in the prompt. If the context is insufficient, the model must defer to the site’s contact form. Because the corpus is small, the context fits in the prompt window directly, avoiding the overhead and complexity of RAG or a vector database.
3. Verify the Requester
Because the chatbot is public, every incoming request passes Cloudflare Turnstile verification and server-side rate limiting before invoking any models. Real users experience invisible validation, while suspicious traffic faces an explicit challenge, keeping bot requests from consuming compute and API quotas.
4. Cap Tokens on Both Ends
Hard limits are invaluable guardrails: the chatbot enforces a 500-character input cap, a 600-token output limit, and a maximum of 10 history turns. This accommodates legitimate inquiries while strictly bounding execution costs and latency.
5. Match the Model to the Task
Factual questions over a fixed, compact dataset do not require expensive, state-of-the-art flagship models. Using lightweight models like gpt-4o-mini for generation and claude-3-5-haiku for evaluation keeps the pipeline fast, cheap, and robust. For evaluation, the pipeline uses structured tool calling to force a clean JSON response containing is_acceptable, reason, and detected_language. This structured boundary keeps the evaluator highly reliable. Start with the simplest model that works; upgrade only when you have evidence it is failing.
6. Fail Gracefully
When both pipeline attempts fail evaluation, the app serves a pre-configured, static response. Retrying a third time with the same input and context is highly unlikely to succeed and only inflates costs. Designing a deterministic fallback path ensures a clean user experience even when the models struggle.
Bonus: Translation for Free
While all site context is in English, the pipeline automatically detects the user’s input language and responds in kind. This multilingual capability is completely emergent, requiring no explicit translation step. The evaluator detects the language, and the generator drafts the response in that language, creating a localized experience out of the box.
See It in Action
To see these guardrails in action, open the live chat on my homepage and toggle “Show pipeline”. Server-Sent Events (SSE) stream each execution stage, including rejected drafts and the evaluator’s reasoning, to the UI as it runs. Rejected drafts appear only in the trace; the user always sees an accepted answer or the safe fallback. For a detailed breakdown of the technical stack, decoupled frontend/backend architecture, and platform implementation details, review the AI Chatbot project page.
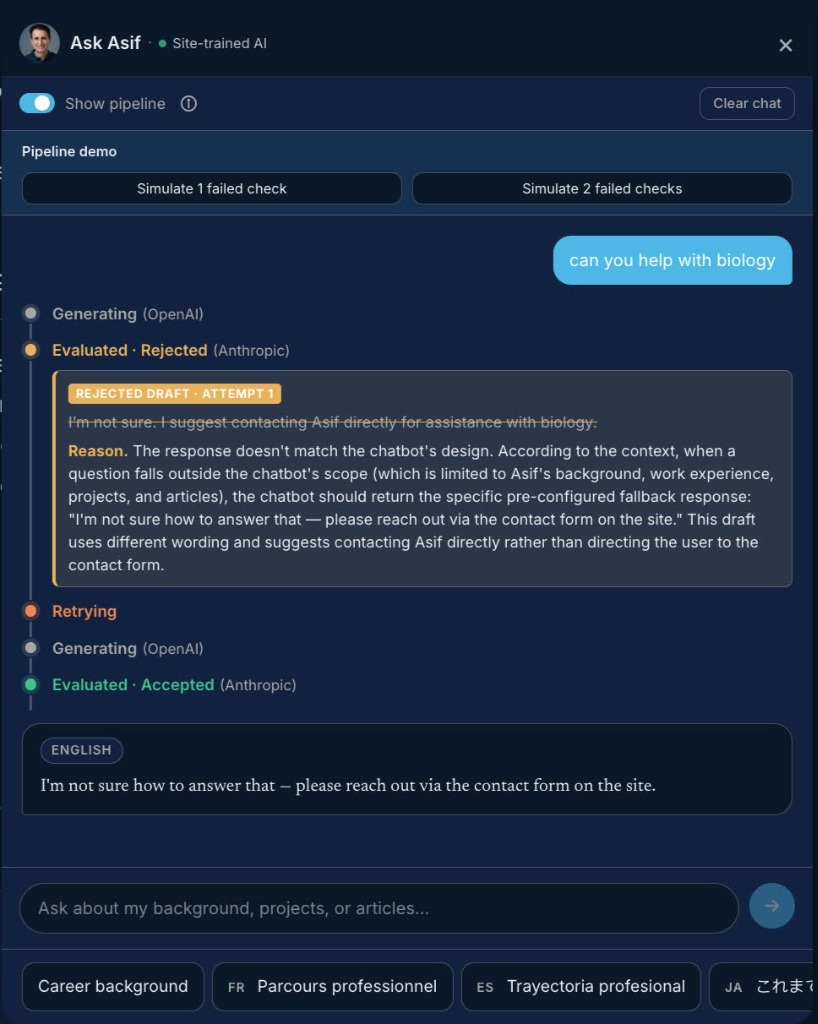
Figure: The chat widget in pipeline mode, visualizing how SSE stages stream live from the pipeline.
A quick caveat: This level of rigor is for public-facing features—even a simple portfolio chatbot like this one—where cost predictability, brand safety, and reliability are paramount. For internal developer tools or private slackbots, you can run a much lighter stack—but if it’s public and unmonitored, safety cannot be an afterthought.
Key Takeaways
- Cross-validate outputs. Using an independent model with structured verification (like tool-based schemas) catches generator failures. Feeding rejection reasoning back for a single retry solves most formatting or content alignment issues.
- Avoid overengineering. Start with the simplest possible architecture. Do not introduce complex components like RAG, vector databases, or autonomous orchestrator agents until you have concrete evidence that a well-crafted system prompt with static context cannot get the job done.
- Layer your defenses. No single guardrail is foolproof. Combining network rate limiting, bot challenges, token budgets, prompt containment, and structured validation forms a robust defense-in-depth.
- Choose models for the job. A fast, cost-efficient model like
gpt-4o-miniis ideal for generation when paired with a highly structured evaluator. Save frontier models for highly complex tasks.